Shared Nothing Hyper-V Infrastructure
The “standard” way to build a VM farm involves centralised storage, usually some form of SAN, with a number of compute nodes. The result is an infrastructure that looks something like this:
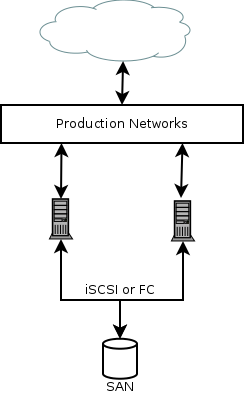
I’ll admit the picture is somewhat simplified but it covers the core elements. The idea behind such an arrangement is that you can ramp up the number of compute nodes as needed. You protect against any of those nodes failing by making use of the High Availability (HA) or Fault Tolerance (FT) features of your VM platform.
Catch is, most of these solutions require shared storage in order to provide the FT or HA features. That means everything relies on that single SAN in the middle of the diagram*.
That’s not so bad when you’ve got an all-singing all-dancing solution with redundant PSUs and controllers, multipath on your iSCSI links and an incredible support contract. If you’re building a proper data centre, this is generally the approach to go for.
But what about those branch offices? You see, in the broadcast world, we tend to get a bit paranoid about hardware redundancy. Outages on critical servers (think SQL, DC and file servers in a local radio station) tend to make silence on air. That gets noticed.
However, fitting £50k+ worth of servers and storage just to provide hardware redundancy for what’s effectively two or thee VMs feels wasteful. Especially when you realise most of the time this hardware will be practically idling.
The rise of converged and hyper-converged systems has considerably widened our options. Even if it generally limits us to HA rather than FT.
That said, we’ve been going for systems like Stratus EverRun. It’s a software solution that allows us to run a “shared nothing” pair of servers. VMs run in pairs of compute instances, always synchronised and ready to take over on a failure.
The task I was set with was to replicate this as much as possible using Hyper-V. After all, you get it (effectively) for free when you’re buying the Windows Server operating system anyway.
Is it possible to provide a FT shared-nothing two node cluster? The short answer is no. The longer answer is that you can get most of the way there and provide a two node HA service.
One of the biggest hurdles to this is the lack of shared storage for Hyper-V. According to Microsoft’s own documentation, the only thing you can do here is DR replication. Any failover would have to be manually actioned or rely on a home-brew script.
While not world ending, it didn’t strike me as the most elegant solution. Cue some investigation into the clustered storage options available on Windows Server 2012.
Turns out Microsoft’s got a feature in Windows Server 2012 called scale-out file server. It’s designed entirely for applications like virtualisation, rather than user data storage.
There are a couple of catches though. A bit like ZFS in the UNIX/Linux world, it really wants direct access to your disks. So much so that it’ll not use disks attached through a RAID controller. Believe me, even changing the PERC settings on a Dell server to present the disks directly wasn’t enough to convince Windows Server.
The second catch, is that much like the SAN solutions that we talked about earlier, this is really built for much bigger deployments. You can’t run scale-out file server and Hyper-V clustering on the same cluster.
That means you’ll need a second set of servers in order to make it work and thus an increase in hardware cost. It’s all becoming quite complicated for that branch office we want some simple hardware redundancy in.
So, while the system works and allows us to take advantage of Hyper-V’s HA capabilities, it’s not quite meeting the requirements for our problem.
The next option I looked into was virtual NAS appliances. There are many of these on the market but we really looked into one of the most popular options – StarWind.
They’ve got an in-depth step-by-step guide on how to set up their software on a two node Hyper-V cluster. Follow it, wait a while as everything synchronises and your storage is almost ready to go.
You will need to add the disks presented through the iSCSI interface to the Hyper-V cluster. Once that’s done, their software will handle the replication and redundancy elements (assuming you’ve set up multi-path correctly).
It should be noted that you’ll need at least two LUNs. One of these will be a small quorum disk. It’s used by each node to confirm they’re still connected to the cluster.
Split brain is something you really want to be thinking about in a two node cluster. You’ll need to carefully design how the system is structured to prevent the link between the two nodes disappearing.
EverRun solves this problem using redundant links between the two physical hosts. From what I can see (but haven’t tested!), StarWind’s software should be able to cope with redundant links.
While we’re on the topic, quorum proved itself a real problem when I was experimenting with two Hyper-V nodes tied back to a FreeNAS box over iSCSI. Without any third party quorum (disk, server, etc.), the hard failure of a single node would result in the complete failure of the cluster.
The reason for this is that the remaining server couldn’t guarantee it was still connected to the live cluster. To prevent split brain occurring, the server would shut down all running VMs.
The result of all this is that it is entirely possible to have a shared nothing two node Hyper-V cluster. You’ll need an external virtual NAS appliance to do it. You’ll also only get HA rather than FT.
That said, it’s not a bad solution for the cost. Even if it is a little unusual.
*Yes, I know you can make VMware use NFS for storage. It’s also possible to build a clustered NFS server (even if it causes me to have bad flashbacks to DRBD and split brains).